str='<p>一年来个人工作总结(精选4篇)</p><h2><a href="//2tu3.com/gangweizhize/">一年来个人工作总结</a> 篇1</h2><p> ' pi = re.compile(r'<a href="//[a-zA-Z0-9.?/&=:]*">', re.S) str= re.sub(pi,'',str) str= str.replace('</a>', '')
使用’ jieba.analyse.extract_tags() ‘提取文档的关键词
import os import codecs import jieba from jieba import analyse import pandas def tags(title): tags = jieba.analyse.extract_tags(title, topK=3) # 采用jieba.analyse.extrack_tags(content, topK)提取关键词 tags=(",".join(str(i) for i in tags))#用逗号隔开 return tags
Python fitz模块导入出错的解决我们不应该仅仅使用pip install fitz来安装fitz,而是同时安装fitz和PyMuPDF(一定注意安装顺序:先安装fitz,然后安装pymupdf,如果顺序相反则无法导入)另外注意:不能只安装PyMuPDF,当只安装PyMuPDF时,虽然可以用import fitz,但是运行fitz.open()等会出错
import re,requestsdef parse_response(url): header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/63.0.3239.132 Safari/537.36 ' } response = requests.get(url, headers=header, timeout=2) response.encoding = 'UTF-8' html = response.text pattern = re.compile('<title>(.*?)</title>', re.S) items = re.findall(pattern, html) print(items[0]) return itemsif __name__ == "__main__": url=input('输入网址:') parse_response(url)
#以空格符分隔符 list = [1,2,3,4] print(" ".join(str(i) for i in list)) #输出结果为:1 2 3 4(注意,此时4后面没有空格啦) #以逗号为分隔符 list = [1,2,3,4] print(",".join(str(i) for i in list)) #输出结果为:1,2,3,4(注意,此时4后面没有逗号)
x = ["a", "", "", "","b"] x = [i for i in x if i] print(x) ["a","b"]
x = ["a", "", "", "","b"] print(set(x)) { '', 'a', 'b'}
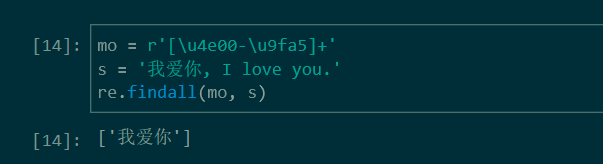
用 ‘[\u4e00-\u9fa5]‘ 匹配中文
在字符串中匹配中文
示例:
匹配字符串中的第一个中文字符
匹配字符串中的第一个连续的中文片段
匹配字符串中的所有中文字符
注:要确保正则字符和匹配文本是 unicode 范围内的编码。
其他 扩充 范围
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
来源:Python匹配中文的正则表达式_python_脚本之家 (jb51.net)
str.isalnum() 判断所有字符是否由数字和字母组合 str.isalpha() 判断所有字符都是字母 str.isdigit() 判断所有字符都是数字 str.islower() 判断所有字符都是小写 str.isupper() 判断所有字符都是大写 str.istitle() 判断所有单词都是首字母大写,像标题 str.isspace() 判断所有字符都是空白字符、\t、\n、\r
break 语句
break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
break语句用在while和for循环中。
如果您使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。
continue 语句
Python continue 语句跳出本次循环,而break跳出整个循环。
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中。
zimu= "ABCDEFGHIJKLMNOPQRSTUVWXYZ" zi= "CD" result = zi in zimu print(result) 结果: True
已加载全部内容
已经没有更多文章了
微信扫一扫获取验证码(回复:验证码)



 正在加载中...
正在加载中...  已加载全部内容 正在加载中... 已加载全部内容
已加载全部内容 正在加载中... 已加载全部内容